 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponentially Consistent Low-Complexity Outlier Hypothesis Testing for Continuous Sequences
Jan 27, 2026In this work, we revisit outlier hypothesis testing and propose exponentially consistent, low-complexity fixed-length tests that achieve a better tradeoff between detection performance and computational complexity than existing exhaustive-search methods. In this setting, the goal is to identify outlying sequences from a set of observed sequences, where most sequences are i.i.d. from a nominal distribution and outliers are i.i.d. from a different anomalous distribution. While prior work has primarily focused on discrete-valued sequences, we extend the results of Bu et al. (TSP 2019) to continuous-valued sequences and develop a distribution-free test based on the MMD metric. Our framework handles both known and unknown numbers of outliers. In the unknown-count case, we bound the detection performance and characterize the tradeoff among the exponential decay rates of three types of error probabilities. Finally, we quantify the performance penalty incurred when the number of outliers is unknown.
Dual-Attention Heterogeneous GNN for Multi-robot Collaborative Area Search via Deep Reinforcement Learning
Jan 07, 2026In multi-robot collaborative area search, a key challenge is to dynamically balance the two objectives of exploring unknown areas and covering specific targets to be rescued. Existing methods are often constrained by homogeneous graph representations, thus failing to model and balance these distinct tasks. To address this problem, we propose a Dual-Attention Heterogeneous Graph Neural Network (DA-HGNN) trained using deep reinforcement learning. Our method constructs a heterogeneous graph that incorporates three entity types: robot nodes, frontier nodes, and interesting nodes, as well as their historical states. The dual-attention mechanism comprises the relational-aware attention and type-aware attention operations. The relational-aware attention captures the complex spatio-temporal relationships among robots and candidate goals. Building on this relational-aware heterogeneous graph, the type-aware attention separately computes the relevance between robots and each goal type (frontiers vs. points of interest), thereby decoupling the exploration and coverage from the unified tasks. Extensive experiments conducted in interactive 3D scenarios within the iGibson simulator, leveraging the Gibson and MatterPort3D datasets, validate the superior scalability and generalization capability of the proposed approach.
Exponentially Consistent Statistical Classification of Continuous Sequences with Distribution Uncertainty
Oct 29, 2024In multiple classification, one aims to determine whether a testing sequence is generated from the same distribution as one of the M training sequences or not. Unlike most of existing studies that focus on discrete-valued sequences with perfect distribution match, we study multiple classification for continuous sequences with distribution uncertainty, where the generating distributions of the testing and training sequences deviate even under the true hypothesis. In particular, we propose distribution free tests and prove that the error probabilities of our tests decay exponentially fast for three different test designs: fixed-length, sequential, and two-phase tests. We first consider the simple case without the null hypothesis, where the testing sequence is known to be generated from a distribution close to the generating distribution of one of the training sequences. Subsequently, we generalize our results to a more general case with the null hypothesis by allowing the testing sequence to be generated from a distribution that is vastly different from the generating distributions of all training sequences.
Exponentially Consistent Outlier Hypothesis Testing for Continuous Sequences
May 02, 2024In outlier hypothesis testing, one aims to detect outlying sequences among a given set of sequences, where most sequences are generated i.i.d. from a nominal distribution while outlying sequences (outliers) are generated i.i.d. from a different anomalous distribution. Most existing studies focus on discrete-valued sequences, where each data sample takes values in a finite set. To account for practical scenarios where data sequences usually take real values, we study outlier hypothesis testing for continuous sequences when both the nominal and anomalous distributions are \emph{unknown}. Specifically, we propose distribution free tests and prove that the probabilities of misclassification error, false reject and false alarm decay exponentially fast for three different test designs: fixed-length test, sequential test, and two-phase test. In a fixed-length test, one fixes the sample size of each observed sequence; in a sequential test, one takes a sample sequentially from each sequence per unit time until a reliable decision can be made; in a two-phase test, one adapts the sample size from two different fixed values. Remarkably, the two-phase test achieves a good balance between test design complexity and theoretical performance. We first consider the case of at most one outlier, and then generalize our results to the case with multiple outliers where the number of outliers is unknown.
Autonomous and Adaptive Role Selection for Multi-robot Collaborative Area Search Based on Deep Reinforcement Learning
Dec 04, 2023In the tasks of multi-robot collaborative area search, we propose the unified approach for simultaneous mapping for sensing more targets (exploration) while searching and locating the targets (coverage). Specifically, we implement a hierarchical multi-agent reinforcement learning algorithm to decouple task planning from task execution. The role concept is integrated into the upper-level task planning for role selection, which enables robots to learn the role based on the state status from the upper-view. Besides, an intelligent role switching mechanism enables the role selection module to function between two timesteps, promoting both exploration and coverage interchangeably. Then the primitive policy learns how to plan based on their assigned roles and local observation for sub-task execution. The well-designed experiments show the scalability and generalization of our method compared with state-of-the-art approaches in the scenes with varying complexity and number of robots.
See the Near Future: A Short-Term Predictive Methodology to Traffic Load in ITS
Jan 08, 2017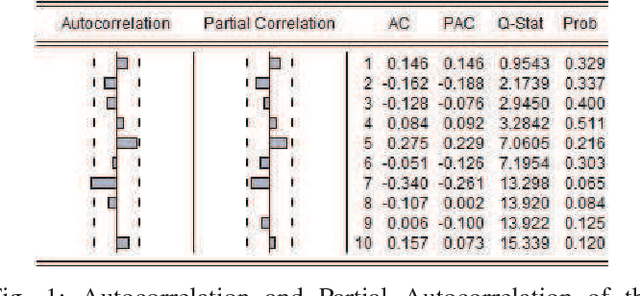
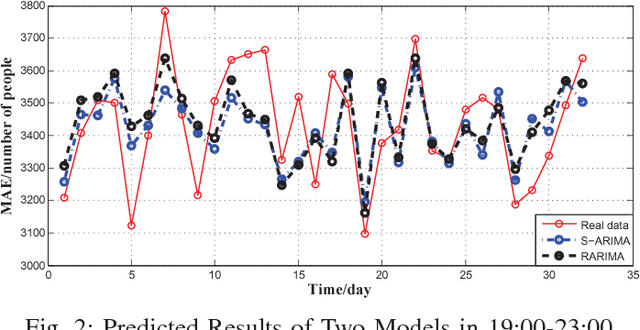
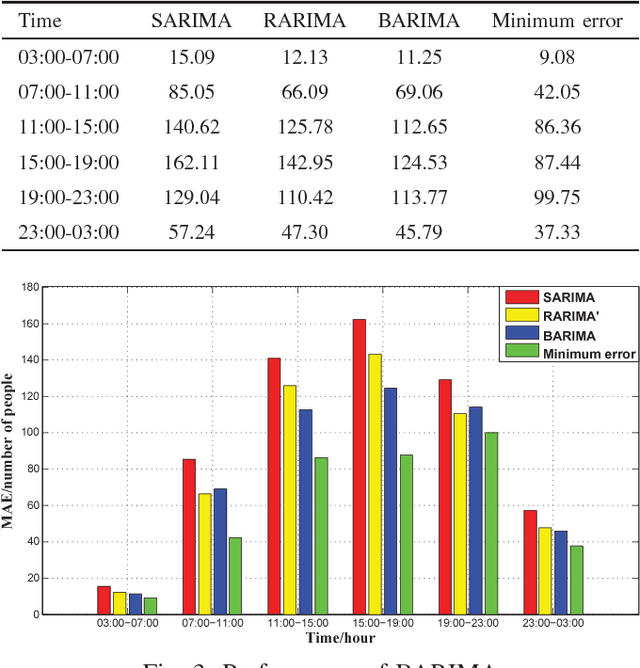
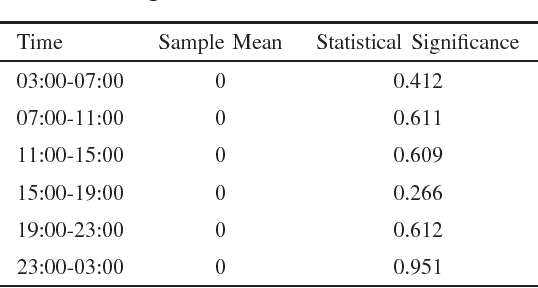
The Intelligent Transportation System (ITS) targets to a coordinated traffic system by applying the advanced wireless communication technologies for road traffic scheduling. Towards an accurate road traffic control, the short-term traffic forecasting to predict the road traffic at the particular site in a short period is often useful and important. In existing works, Seasonal Autoregressive Integrated Moving Average (SARIMA) model is a popular approach. The scheme however encounters two challenges: 1) the analysis on related data is insufficient whereas some important features of data may be neglected; and 2) with data presenting different features, it is unlikely to have one predictive model that can fit all situations. To tackle above issues, in this work, we develop a hybrid model to improve accuracy of SARIMA. In specific, we first explore the autocorrelation and distribution features existed in traffic flow to revise structure of the time series model. Based on the Gaussian distribution of traffic flow, a hybrid model with a Bayesian learning algorithm is developed which can effectively expand the application scenarios of SARIMA. We show the efficiency and accuracy of our proposal using both analysis and experimental studies. Using the real-world trace data, we show that the proposed predicting approach can achieve satisfactory performance in practice.